Lua 字串/字元
字串(String)是由數字、字母、底線组成的一串字元。
Lua 語言中字符串可以使用以下三種方式來表示:
- 單引號間的一串字符。
- 雙引號間的一串字符。
- [[ 和 ]] 間的一串字符。
以上三種方式的字符串實例如下:
string1 = "Lua"
print("\"字串 1 是\"", string1)
string2 = 'runoob.com'
print("字串 2 是", string2)
string3 = [["Lua 教程"]]
print("字串 3 是", string3)
以上代碼執行输出结果為:
"字符串 1 是" Lua
字符串 2 是 runoob.com
字符串 3 是 "Lua 教程"
轉義字符用於表示不能直接顯示的字符,比如後退鍵,返回鍵,等。如在字符串轉換雙引號可以使用 "\""。
所有的轉義字符和所對應的意義:
| 轉義字符 | 意義 | ASCII碼值(十進制) |
|---|---|---|
| \a | 響鈴(BEL) | 007 |
| \b | 退格(BS) ,將當前位置移到前一列 | 008 |
| \f | 換頁(FF),將當前位置移到下頁開頭 | 012 |
| \n | 換行(LF) ,將當前位置移到下一行開頭 | 010 |
| \r | 返回(CR) ,將當前位置移到本行開頭 | 013 |
| \t | 水平制表(HT) (跳到下一個TAB位置) | 009 |
| \v | 垂直制表(VT) | 011 |
| \ | 代表一個反斜線字符''\' | 092 |
| \' | 代表一個單引號字符 | 039 |
| \" | 代表一個雙引號字符 | 034 |
| \0 | 空字符(NULL) | 000 |
| \ddd | 1到3位八進制數所代表的任意字符 | 三位八進制 |
| \xhh | 1到2位十六進制所代表的任意字符 | 二位十六進制 |
字串操作
Lua 提供了很多的方法來支持字符串的操作:
| 序號 | 方法 | 用途 | 範例 |
|---|---|---|---|
| 1 | string.upper(argument) | 字串全部轉為大寫字母。 | |
| 2 | string.lower(argument) | 字串全部轉為小寫字母。 | |
| 3 | string.gsub(mainString,findString,replaceString,num) | 在字串中替換,mainString為要替換的字串, findString 為被替換的字符,replaceString 要替換的字符,num 替換次數(可以忽略,則全部替換) | 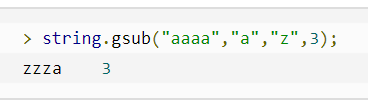 |
| 4 | string.find (str, substr, [init, [end]]) | 在一個指定的目標字符串中搜索指定的内容(第三個參數為索引),返回其具體位置。不存在則返回 nil。 |  |
| 5 | string.reverse(arg) | 字串反轉 |  |
| 6 | string.format(...) | 返回一個類似 printf 的格式化字串 |  |
| 7 | string.char(arg) 和 string.byte(arg[,int]) | char 將整型數字轉成字元並連接, byte 轉換字符為整數值(可以指定某個字元,默任第一個字元)。 |  |
| 8 | string.len(arg) | 計算字串長度。 |  |
| 9 | string.rep(string, n) | 返回字串 string 的 n 個拷貝 |  |
| 10 | .. | 連接兩個字串或字元 |  |
| 11 | string.gmatch(str, pattern) | 回一个迭代器函數,每一次使用這個函數,返回一個在字串 str 找到的下一个符合 pattern 描述的子字串。如果参数 pattern 描述的字串没有找到,迭代函數返回nil。 |  |
| 12 | string.match(str, pattern, init) | string.match()只尋找來源字串 str 中的第一個配對, 參數 init 可選,指定搜尋過程的起點,默認為1。 在成功配對時,函數將返回配對表達式中的所有捕獲結果; 如果没有設置捕獲標記,則返回整個配對字符串,當没有成功的配對時,返回 nil。 |  |
字串大小寫轉換
以下實例演示了如何對字符串大小寫進行轉換:
string1 = "Lua"
print(string.upper(string1))
print(string.lower(string1))
以上代碼執行结果為:
LUA
lua
字串查找與反轉
以下實例演示了如何對字符串進行查找與反轉操作:
string = "Lua Tutorial"
-- 查找字串
print(string.find(string, "Tutorial"))
reversedString = string.reverse(string)
print("新字串為", reversedString)
以上代碼執行结果為:
5
12
新字符串為 lairotuT auL
字符串格式化
Lua 提供了 string.format() 函數來生成具有特定格式的字符串,函數的第一個參數是格式,之後是對應格式中每個代號的各種數據。
由於格式字符串的存在,使得產生的長字符串可讀性大大提高了。這個函數的格式很像 C 語言中的 printf()。
以下實例演示了如何對字符串進行格式化操作:
格式字符串可能包含以下的轉義碼:
- %c - 接一個數字, 並將其轉化為ASCII碼表中對應的字符
- %d, %i - 接受一個數字並將其轉化為有符號的整數格式
- %o - 接受一個數字並將其轉化為八進制數格式
- %u - 接受一個數字並將其轉化為無符號整数格式
- %x - 接受一個數字並將其轉化為十六進制數格式,使用小寫字母
- %X - 接受一個數字並將其轉化為十六進制數格式,使用大寫字母
- %e - 接受一個數字並將其轉化為科學記號法格式,使用小寫字母 e
- %E - 接受一個數字並將其轉化為科學記號法格式,使用大寫字母 E
- %f - 接受一個數字並將其轉化為浮點數格式
- %g(%G) - 接受一個數字並將其轉化為%e(%E, 對應%G)及 %f 中較短的一種格式
- %q - 接受一個字符串並將其轉化為可安全被 Lua 編譯器讀入的格式
- %s - 接受一個字符串並按照给定的參數格式化該字串
為進一步细分格式,可以在 % 號後添加參數,參數將以如下的順序讀入:
- (1) 符号:一個+号表示其後的數字轉義符將讓正數顯示正號,默認情况下只有負數顯示符号
- (2) 點位符:一個0,在后面指定了字串寬度时占位用,不填时的默认占位符是空格
- (3) 對齊標示:在指定了字串寬度時,默認為右對齊,增加-号可以改为左对齐
- (4) 宽度数值
- (5) 小數位數/字串裁切:在寬度數值後增加的小數部分 n,若後接 f (浮點數轉義符,如:%6.3f)則設定該浮点數的小數只保留n位,若後接 s (字符串轉義符,如:%5.3s)則設定該字符串只顯示前 n 位
string1 = "Lua"
string2 = "Tutorial"
number1 = 10
number2 = 20
-- 基本字串格式化
print(string.format("基本格式化 %s %s", string1, string2))
-- 日期格式化
date = 2
month = 1
year = 2014
print(string.format("日期格式化 %02d/%02d/%03d", date, month, year))
-- 十進制格式化
print(string.format("%.4f", 1/3))
以上代碼執行结果為:
基本格式化 Lua Tutorial
日期格式化 02/01/2014
0.3333
其他例子:
string.format("%c", 83) 輸出 S
string.format("%+d", 17.0) 輸出 +17
string.format("%05d", 17) 輸出 00017
string.format("%o", 17) 輸出 21
string.format("%u", 3.14) 輸出 3
string.format("%x", 13) 輸出 d
string.format("%X", 13) 輸出 D
string.format("%e", 1000) 輸出 1.000000e+03
string.format("%E", 1000) 輸出 1.000000E+03
string.format("%6.3f", 13) 輸出 13.000
string.format("%q", "One\nTwo") 輸出 "One\
Two"
string.format("%s", "monkey") 輸出 monkey
string.format("%10s", "monkey") 輸出 monkey
string.format("%5.3s", "monkey") 輸出 mon
字串與整數相互轉換
以下實例演示了字串與整數相互轉換:
-- 字串轉換
-- 轉換第一個字串
print(string.byte("Lua"))
-- 轉換第三個字串
print(string.byte("Lua", 3))
-- 轉換末尾第一個字元
print(string.byte("Lua", -1))
-- 第二個字元
print(string.byte("Lua", 2))
-- 轉換末尾第二个字元
print(string.byte("Lua", -2))
-- 整數 ASCII 碼轉換為字元
print(string.char(97))
以上代碼執行结果為:
76
97
97
117
117
a
其他常用函数
以下實例演示了其他字(元)串操作,如計算字(元)串長度,字串連接,字(元)串複製等:
string1 = "www."
string2 = "runoob"
string3 = ".com"
-- 使用..进行字符串连接
print("连接字符串", string1..string2..string3)
-- 字符串长度
print("字符串长度 ", string.len(string2))
-- 字符串复制2次
repeatedString =string.rep(string2, 2)
print(repeatedString)
以上代碼執行结果為:
連接字符串 www.runoob.com
字符串長度 6
runoobrunoob
匹配模式
Lua 中的匹配模式直接用常規的字符串來描述。 它用於模式匹配函数 string.find, string.gmatch, string.gsub, string.match。
你還可以在模式串中使用字符類。
字符類指可以匹配一個特定字符集合内任何字符的模式項。比如,字符類 %d 匹配任意數字。所以你可以使用模式串 '%d%d/%d%d/%d%d%d%d' 搜尋 dd/mm/yyyy 格式的日期:
s = "Deadline is 30/05/1999, firm"
date = "%d%d/%d%d/%d%d%d%d"
print(string.sub(s, string.find(s, date))) --> 30/05/1999
下面的表列出了 Lua 支持的所有字元類:
單個字元(除 ^$()%.[]*+-? 外):與該字符自身配對
- .(點):與任何字符配對
- %a:與任何字母配對
- %c:與任何控制符配對(例如:\n)
- %d:與任何數字配對
- %l:與任何小寫字母配對
- %p:與任何標點(punctuation)配對
- %s:與空白字元配對
- %u:與任何大寫字母配對
- %w:與任何字母/數字配對
- %x:與任何十六進制數配對
- %z:與任何代表0的字符配對
- %x(此處x是非字母非數字字元):與字符 x 配對。主要用来處理表達式中有功能的字符(^$()%.[]*+-?)的配對問题, 例如%%與%配對
- [數个字符类]:與任何[]中包含的字符類配對。例如[%w_]與任何字母/數字, 或底線符号(_)配對
- [^數个字符类]:與任何不包含在[]中的字元類配對。例如[^%s]與任何非空白字符配對
當上述的字元類用大寫書寫時, 表示與非此字元類的任何字符配對。例如:%S 表示與任何非空白字符配对.例如,'%A' 非字母的字元:
> print(string.gsub("hello, up-down!", "%A", "."))
hello..up.down.4
數字4不是字串结果的一部分,他是 gsub 返回的第二個结果,代表發生替換的次數。
在模式匹配中有一些特殊字符,他们有特殊的意義,Lua中的特殊字符如下:
( ) . % + - * ? [ ^ $
'%' 用作特殊字符的轉義字符,因此 '%.' 匹配点;'%%' 匹配字符 '%'。轉義字符 '%' 不僅可以用来轉義特殊字元,還可以用於
所有的非字母的字元。
模式條目可以是:
- 單個字元類匹配該類别中任意單個字元;
- 單個字元類跟一個 '
*', 將匹配零或多個該類的字元。 這個條目總是匹配盡可能長的串; 單個字元類跟一個 '
+', 將匹配一或更多個該類的字元。 這個條目是匹配盡可能長的串;單個字元類跟一個 '
-', 將匹配零或更多個該類的字元。 和 '*' 不同, 這個條目總是匹配盡可能短的串;單個字元類跟一個 '
?', 将匹配零或一個該類的字元。 只要有可能,它會匹配一个;%n, 這裡的 n 可以從 1 到 9; 這個條目匹配一個等於 n 號捕獲物(后面有描述)的子串。%bxy, 這裡的 x 和 y 是兩個明確的字元; 這個條目匹配以 x 開始 y 结束, 且其中 x 和 y 保持 平衡 的字符串。 意思是,如果从左到右讀這個字符串,對每次讀到一個 x 就 +1,讀到一个 y 就 -1, 最终结束處的那个 y 是第一個記數到 0 的 y。 舉個例子,條目%b()可以匹配到括號平衡的表達式。%f[set], 指边境模式; 這個條目會匹配到一個位於 set 内某個字元之前的一個空串, 且這個位置的前一個字符不屬於 set。 集合 set 的含義如前面所述。 匹配出的那個空串之開始和結束點的計算就看成該處有個字符 '\0' 一樣。
模式:
模式指一個模式條目的序列。 在模式最前面加上符號 '^' 將描定從字符串的開始處做匹配。 在模式最後面加上符號 '$' 將使匹配過程描定到字符串的结尾。 如果 '^' 和 '$' 出現在其它位置,它們均没有特殊含義,只表示自身。
捕獲:
模式可以在内部用小括號括起一個子模式; 這些子模式被稱為捕获物。 當匹配成功時,由捕获物匹配到的字符串中的子串被保存起来用於未来的用途。 捕獲物以它們左括號的次序来編號。 例如,對於模式"(a*(.)%w(%s*))", 字符串中匹配到"a*(.)%w(%s*)"的部分保存在第一個捕獲物中 (因此是编號 1 ); 由 "." 匹配到的字符是 2 號捕獲物, 匹配到 "%s*" 的那部分是 3 号。
作為一個特例,空的捕獲()將捕獲到當前字符串的位置(它是一個數字)。 例如,如果將模式"()aa()"作用到字符串"flaaap"上,將產生兩個捕獲物: 3 和 5 。